Datawhale AI 夏令营
2024 大运河杯数据开发应用创新大赛 - 城市治理赛道
赛题解读

赛题目标
随着城市化进程的加快,城市管理面临着前所未有的挑战。占道经营、垃圾堆放和无照经营游商等问题对城市管理提出了更高的要求。本赛道聚焦城市违规行为的智能检测,要求选手研究开发高效可靠的计算机视觉算法,提升违规行为检测识别的准确度,降低对大量人工的依赖,提升检测效果和效率,从而推动城市治理向更高效、更智能、更文明的方向发展,为居民创造一个安全、和谐、可持续的居住环境。
赛事资源分析
初赛提供城管视频监控数据与对应违规行为标注。违规行为包括垃圾桶满溢、机动车违停、非机动车违停等。视频数据为mp4格式,标注文件为json格式,每个视频对应一个json文件。
frame_id:违规行为出现的帧编号event_id:违规行为IDcategory:违规行为类别bbox:检测到的违规行为矩形框的坐标,[xmin,ymin,xmax,ymax]形式
标注示例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
[
{
"frame_id": 20,
"event_id": 1,
"category": "机动车违停",
"bbox": [200, 300, 280, 400]
},
{
"frame_id": 20,
"event_id": 2,
"category": "机动车违停",
"bbox": [600, 500, 720, 560]
},
{
"frame_id": 30,
"event_id": 3,
"category": "垃圾桶满溢",
"bbox": [400, 500, 600, 660]
}
]
违法评判标准
| 机动车违停 | 非机动车违停 | 垃圾满溢 |
|---|---|---|
| 机动车在设有禁止停车标志、 标线的路段停车,或在非机 动车道、人行横道、施工地 段等禁止停车的地方停车。 | 非机动车(如自行车、电动 车等)未按照规定停放在指 定的非机动车停车泊位或停 车线内,而是在非机动车禁 停区域或未划定的区域 (消防通道、盲道、非机动 车停车区线外、机动车停车 区等)随意停放。 | 生活垃圾收集容器内垃圾超过 三分之二以上即为满溢。垃 圾桶无法封闭、脏污且周边 有纸屑、污渍、塑料、生活 垃圾及杂物堆放。 |
 |  | |
评分规则介绍
使用F1score、MOTA指标来评估模型预测结果。对每个json文件得到两个指标的加权求和,最终得分为所有文件得分取均值。12
其中,F1 Score 是 Precision(精度)和 Recall(召回率)的调和平均值,专注于检测模型的准确性和完整性。 \(F1\_score = 2 \times \frac{Recall \times Precision}{Recall + Precision}\)
- 精度:检测出的正样本中有多少是正确的。模型预测的目标中有多少是真实目标,减少 假阳性( FP) 的比例。
- 召回率:所有真实的正样本中有多少被正确检测出。模型未遗漏多少目标,减少假阴性(FN) 的比例。
F1 Score 是在 Precision 和 Recall 之间找到一个平衡的度量。当这两个指标均衡时,F1 Score 较高。因此,它同时考虑了避免错误检测的目标以及尽量多的检测出所有目标。
MOTA(Multi-Object Tracking Accuracy,多目标追踪准确率)是多目标追踪任务的评估标准,它专注于减少错误检测(假阳性和假阴性)以及 ID 追踪错误(ID Switches, IDSW)
\[MOTA = 1 - \frac{\sum FN + \sum FP + \sum IDSW}{\sum GT}\]MOTA 主要关注:
- 减少漏检(FN):保证模型能够检测出所有目标,尽量不要遗漏。
- 减少误检(FP):保证模型预测出的目标是真实目标,避免错误检测。
- 减少 ID 错误(IDSW):在多目标追踪任务中,减少不同目标的 ID 错误。
最终评分的权重分配则要求模型在检测性能和追踪性能之间取得平衡。重点是模型的检测能力(F1 Score),其次是其在多目标场景下的表现(MOTA)
\[score = 0.85 \times F1\_score + 0.15 \times MOTA\]任务提交格式
初赛任务是根据给定的城管视频监控数据集,进行城市违规行为的检测。违规行为主要包括垃圾桶满溢、机动车违停、非机动车违停等。选手需要能够从视频中分析并标记出违规行为,提供违规行为发生的时间和位置信息。
目标检测系统 - YOLO
You Only Look Once(YOLO),是一种流行的实时目标检测系统,由Joseph Redmon等人在2015年提出。YOLO模型的核心思想是将目标检测任务视为一个单一的回归问题,通过一个卷积神经网络(CNN)直接从图像像素到边界框坐标和类别概率的映射。YOLO模型经过了多次迭代,包括YOLOv2(YOLO9000)、YOLOv3和YOLOv4等版本,每个版本都在性能和速度上有所提升,同时也引入了一些新的技术,如更深的网络结构、更好的锚框机制、多尺度特征融合等。
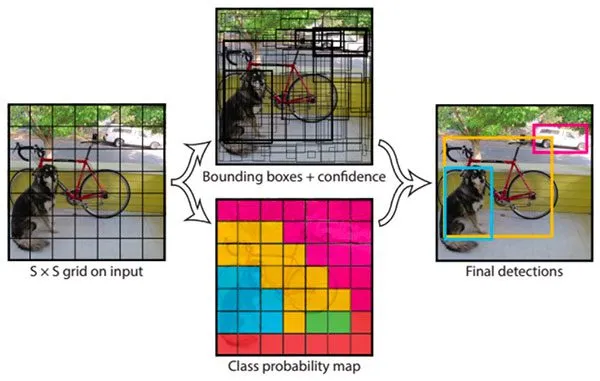
YOLO的特点
- 端到端训练:YOLO 将目标检测任务视为单一的回归问题,可以在一次前向传播中同时预测多个目标的类别和边界框坐标,避免了其他目标检测算法中冗长的候选框生成和分类过程。
- 高效的实时性:由于 YOLO 的网络结构设计和直接回归方法,YOLO 在运行速度上非常快,特别适用于实时场景下的目标检测任务。
- 全局推理:YOLO 对整幅图像进行检测,而不像其他方法仅在局部区域进行预测。这使得 YOLO 对复杂背景和不规则物体具有较好的鲁棒性。
标注格式
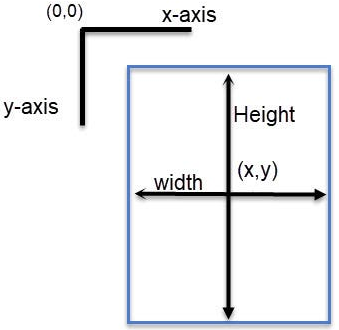
YOLO使用的标注格式是每张图像一个文本文件,文件名与图像文件名相对应。
<class> <x_center> <y_center> <width> <height>
<class>:类别的索引号。<x_center>:边界框中心点的 x 坐标,相对于图像宽度的归一化比例。<y_center>:边界框中心点的 y 坐标,相对于图像高度的归一化比例。<width>:边界框的宽度,相对于图像宽度的归一化比例。<height>:边界框的高度,相对于图像高度的归一化比例。
YOLO标注格式的转换
YOLO 的标注文件只需要记录归一化的坐标,适用于不同大小的图像。
1
2
3
4
5
x_min, y_min, x_max, y_max = bbox
x_center = (x_min + x_max) / 2 / img_width
y_center = (y_min + y_max) / 2 / img_height
width = (x_max - x_min) / img_width
height = (y_max - y_min) / img_height
模型训练
1
2
3
4
5
6
7
from ultralytics import YOLO
# 设置模型版本
model = YOLO("yolov8n.pt")
# 设定数据集和训练参数
results = model.train(data="yolo-dataset/yolo.yaml", epochs=2, imgsz=1080, batch=16)
在模型训练中,可以通过调整以下参数来改进模型:
- 训练轮次(
epoch)epoch决定了模型遍历整个数据集的次数。增加训练的epoch可以让模型更好地学习数据中的模式,减少欠拟合现象。但过多的epoch可能导致过拟合,影响泛化能力。
- 批量大小(
batch):- 批量大小决定了每次训练中传递到模型的图像数量。增加
batch size通常可以使模型的权重更新更加稳定,但需要更多的显存。适当的批量大小可以帮助模型更快收敛,但过大可能导致内存不足。
- 批量大小决定了每次训练中传递到模型的图像数量。增加
- 学习率(
lr0、lrf):- 学习率控制模型权重更新的速度。如果学习率过高,模型可能会跳过最优解;如果学习率过低,模型训练速度会很慢,并且可能陷入局部最优。
训练日志
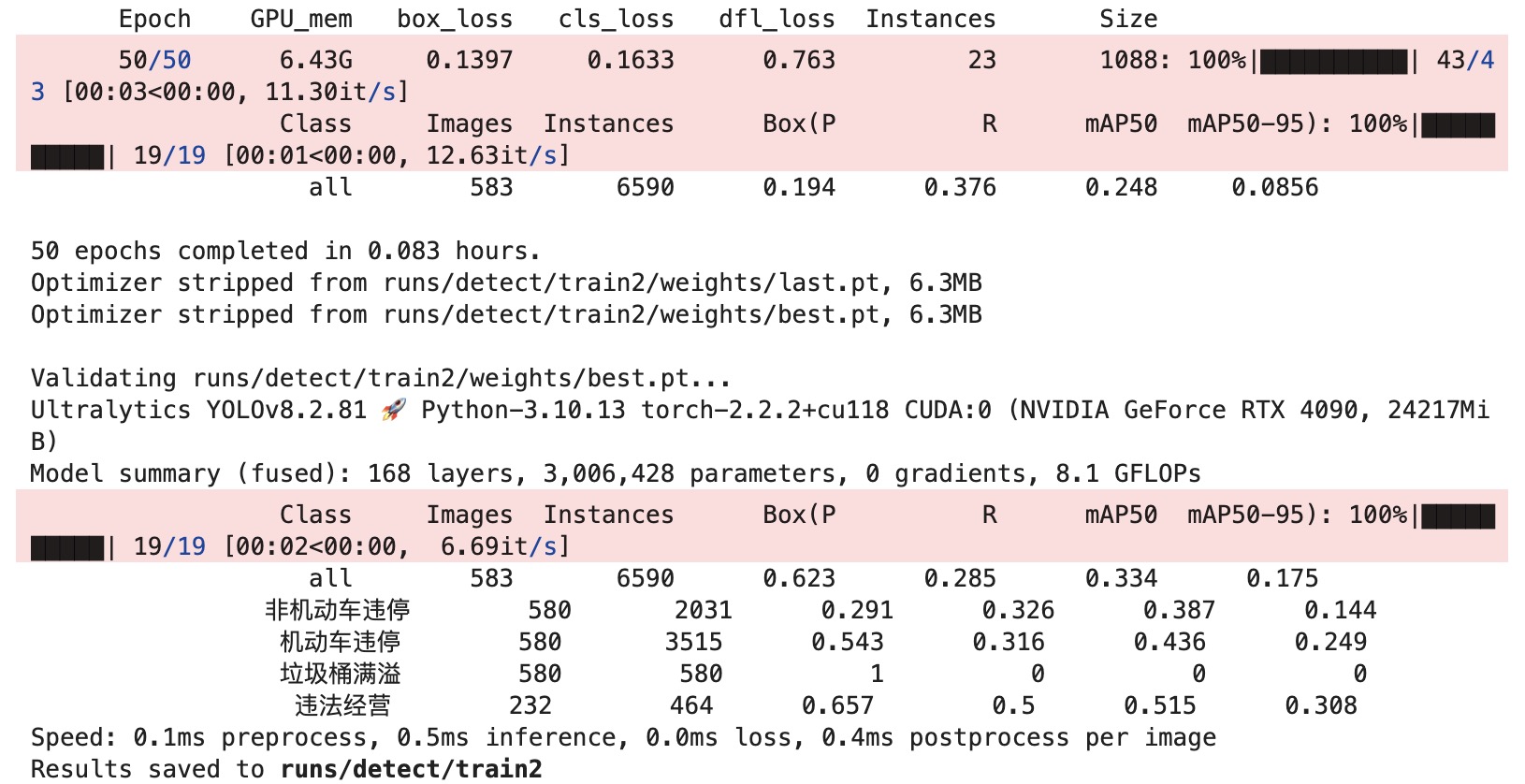
每一个epoch会返回3个损失函数:
- 边界框回归损失
box_loss- 评估模型预测的边界框与真实边界框之间的差异。该损失越小,说明模型在定位物体方面越精确。
- 分类损失
cls_loss是分类损失,用于评估类别预测的准确性。- 衡量模型在类别预测上的准确性。较小的 cls_loss 表明模型能更准确地预测每个目标的类别。
- 防御性损失
dfl_loss- 是一种旨在提高模型泛化能力的损失函数,主要与特征提取和边界框回归的细节优化有关。
其中,边界框回归损失和分类损失的降低有助于提高 F1 Score,而防御性损失通过减少模型的误报和漏报,则间接影响 MOTA 和 F1 Score。
调参
1
2
model = YOLO("yolov8n.pt")
results = model.train(data="yolo-dataset/yolo.yaml", epochs=50, imgsz=1080, batch=32, lr0=0.1, lrf=0.01)
相比初始的模型训练参数设置,调参后的模型在多个类别上的检测效果都有所提升,尤其是精度(Precision)显著提高,对正样本的检测更加准确。以下是调参后的训练日志截图: